Na naší cestě jsme již stihli nasbírat obstojné množství vzorků.
I Meriwether už musel uznat, že je čas natrénovat jimi model Picto. Koneckonců je to jeden z našich hlavních úkolů. Nové vzorky se mi sotva vejdou do batohu.
Vysvětlím ti, jak připravit data pro trénování modelu.
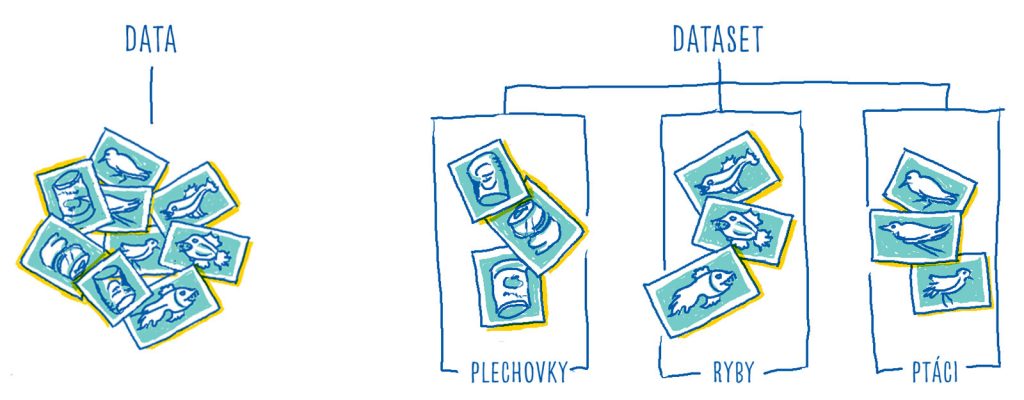
Všechny vzorky, které vidíš u mě v batohu, je nejprve třeba roztřídit do kategorií, jako jsem to dělal s těmi na vodní pohon (v batohu se mi ale zase pomíchaly).
Takto roztříděné vzorky tvoří takzvaný dataset. To jsou zdrojové soubory pro natrénování modelu strojového učení.
Při trénování se díky datasetu naučí model rozpoznávat jednotlivé vzorky od sebe. Pamatuješ na ptáky? Meriwetherův Picto rozpozná letící objekt například díky zobáku a křídlům jako ptáka.
Tak se do toho dáme!
Takhle vypadají některé vzorky, které jsem získal.
Obrázky si stáhni do svého počítače.
Klepni na šipku a soubory se stáhnou.
Stáhl se ti soubor, který se jmenuje „jdeme-trenovat-vzorky.zip“. Je třeba ho takzvaně „rozbalit“. Podívej se na video a zjisti, jak se to dělá. Ale pozor. Způsoby, jak složku rozbalit, se liší.
Po rozbalení bys měl(a) vidět složku s 20 obrázky.
A teď si v obrázcích uděláme pěkně pořádek.
Takhle vypadají jednotliví zástupci 5 kategorií:
Malé vzorky na vodní pohon
Velké vzorky na vodní pohon
Fotosyntetické materiály
Dutá cylindrická tělesa neznámého účelu
Létající vzorky
Podívej, co nás čeká.
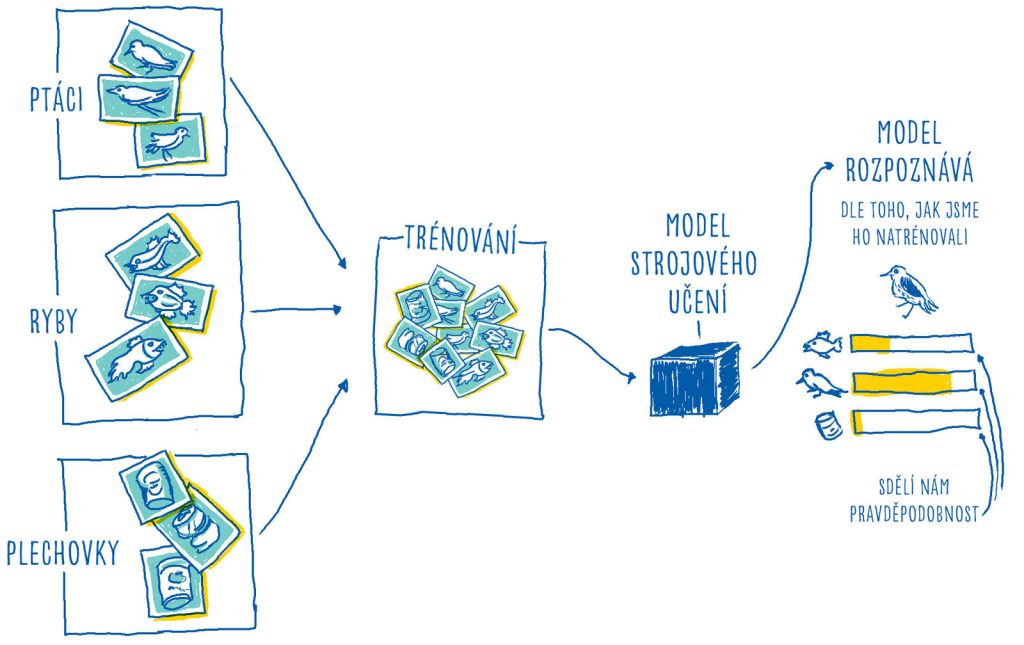
Vzorky se mi v batohu pomíchaly. A tak je roztřídíme do kategorií, abychom vytvořili dataset. Pak model natrénujeme a nakonec ho otestujeme (jestli rozpozná testovací obrázky).
Model budeme trénovat v aplikaci Teachable Machine.
To v překladu znamená „Stroj, který se dokáže učit“. Podívej se na video, ať víš, jak se s ní pracuje.
Teď můžeš rovnou přejít do aplikace.
ALE POZOR! Až model natrénuješ, NEZAVÍREJ stránku Teachable Machine v prohlížeči a vrať se sem za námi zpět!